type
Post
status
Published
date
Dec 28, 2021
slug
build-search-system-part-two-index-analyzer-and-chinese-search
summary
本文整理一下自己在设计漫画搜索索引时候遇到的一些问题和细节
tags
Elasticsearch
EN
category
技术分享
icon
password
Property
Feb 16, 2023 04:28 AM
索引相当于DB中的表,数据都是储存在索引中。正如数据库的表需要设计索引一样,ES的索引设计同样也有很多要注意的地方,否则就会发生查询速度过慢甚至查询不到数据的情况。本文整理一下自己在设计漫画搜索索引时候遇到的一些问题和细节。
the Index just like Table in DB,the data is stored in the Index.Just like DB tables need to be indexed,the ES index also has pay attaton to many points,Otherwise,the query speed will be slow even the data can not be queried. In this post,I will sort out some of the problems and details I encountered when designing the comic search index.
索引结构
一个典型的索引配置如下所示:
A typical Index Configuration like the following show:
{ "mappings": { "properties": { "userid": { "type": "keyword" }, "nick_name": { "type": "text", "analyzer": "nick_analyzer" } } }, "settings": { "index": { "analysis": { "analyzer": { "nick_analyzer": { "filter": [ "stop", "lowercase" ], "tokenizer": "standard" } } }, "number_of_shards": "1", "number_of_replicas": "1" } } }
可以看到配置中分成两个属性:
mappings 和 settings。下面主要分析这两个部分。You can see two properties in the configuration:
mappings and settings.Then let us focus on this two parts.mappings 配置
mappings主要用来声明索引包含哪些字段,并且通过
type主要用来指定字段的类型,一般来说,常用的几个类型如下所示:The mappings is usually used for define what is include in Index and appoint the type of field by
type. In general, several frequently-used type are shown in the below:普通字符串类型
关键词为
keyword。最常用的类型,将原始内容作为完整的一个词储存在倒排索引中,可以看做 mysql 中的varchar类型。不会被分词器处理。The keyword is
keyword.It is the most common type. It store the original content as a complete word in the Inverted Index. It can be thought of varchar type in mysql and will not be processed by the tokenizer.数字类型
包括
long、integer、short、byte、double、float等数字类型,和常见的编程语言中的取值范围保持一致,在查询中可以进行计算。It include
long integer short byte double、float and so on. The value range as same as the common programming language and can be calculated in queries.长文本类型
关键词是
text。用来储存长文本。和 keyword 区别是 text 类型可以通过分词器分词处理,这也是 ES 查询的核心。The keyword is
text.It is used for store long text. The difference between text and keyword is that text can be handled by tokenizer. This is also the core in ES query.日期类型
The keyword is
date. It is also used to store time with the field format. You can assign an accepted time format include second timestamp and Millisecond timestamp and string date. The detail about the accepted time format can be referd by this post like:{ "type": "date", "format": "yyyy-MM-dd||epoch_millis" }
布尔类型
可以接受表示 true 和 false 的字符串或数字,比如:
It can be accepted strings or numbers representing true and false like:
- true: true, "true", "on", "yes", "1"
- false: false, "false", "off", "no", "0"
以上是常用的数据类型。大家也许会发现我没有提到
数组类型。在ES中,数组不需要单独定义,只需要在写入数据的时候,直接将需要的数据以数组的形式写入即可。注意所有的值必须是同一个类型。These are common data types.You may notice that I didn't mention the
array type. In ES you don't have to define array type insead of input the required data as an array directly. The only matter is all the value must be of the same type.setting 配置
正如同 mysql 中建表的同时要指定各种索引(主键索引、联合索引等)一样,ES 中我们也需要通过
setting来确保索引按照我们的需求工作。Just as in mysql we need to specify various indexes(primary index,clustered index),In es we also need
setting to ensure that the index works according to our our requirements.analysis
analysis用于设置索引的分析器。ES 的文本在保存到索引之中时,需要指定唯一的分析器Analyzer(每个字段类型都有默认的分析器),它的作用就是将原文本处理、变形、切分成我们需要的单元,从而方便我们搜索。一个标准的Analyzer包含三个组件,即0~N个Char Filter、一个Tokenizer、0~N个Token Filter。如下图所示:analysis is used to set analyzer for index. When the text is saved to an index We need to specify a unique Analyzer.Its function is to process the original text,transform, cut into the unit we need,so as for searching. A typical Analyzer include three parts:some Char Filter, a Tokenizer and some Token Filter.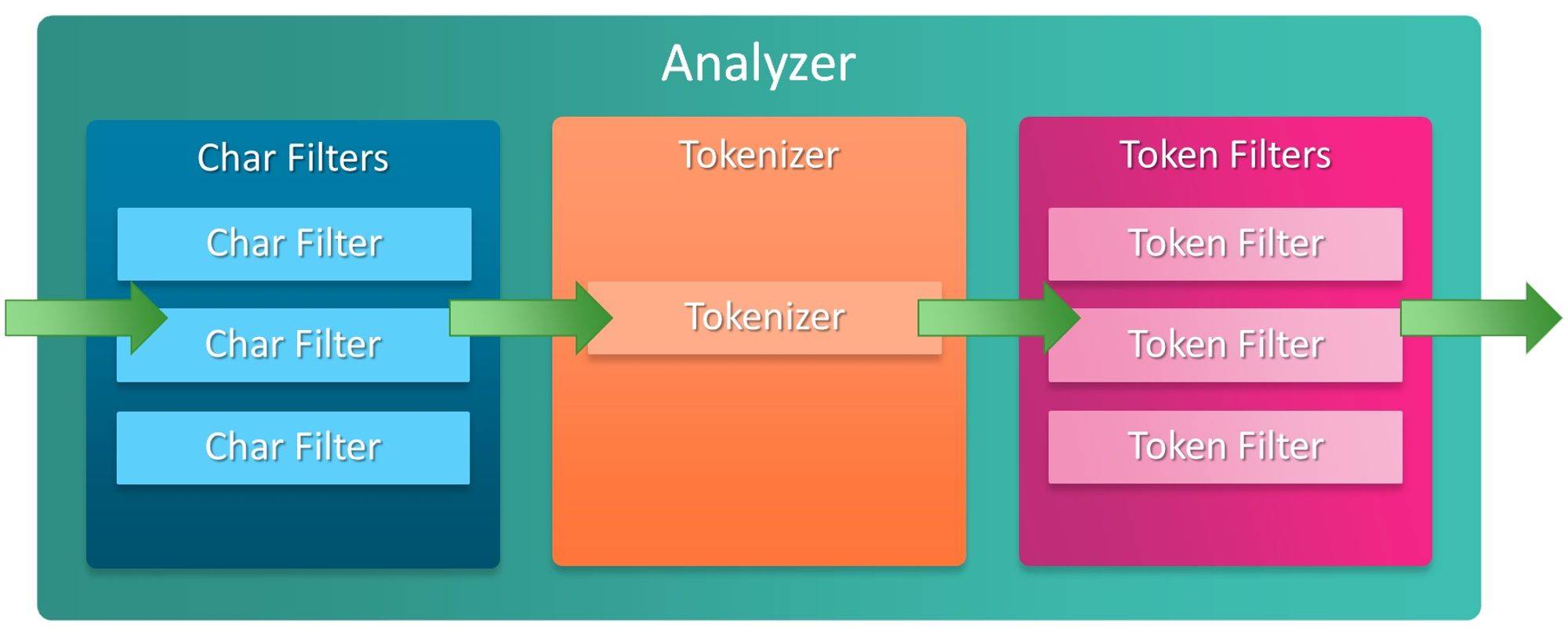
- Char Filter:对文本进行过滤处理,常用来过滤html标签
- Tokenizer:Analyzer的核心部分,对本文进行分词。必须包含一个Tokenizer
- Token Filter:对 Tokenizer 分出的词进行过滤、转换处理。如同义词转换、拼音转换等
- Char Filter:Filter text, often used to filter HTML tags
- Tokenizer:The core part of the Analyzer that split text. must include a Tokenizer
- Token Filter:converts the words which splted from Tokenizer. Such as synonym conversion, pinyin conversion
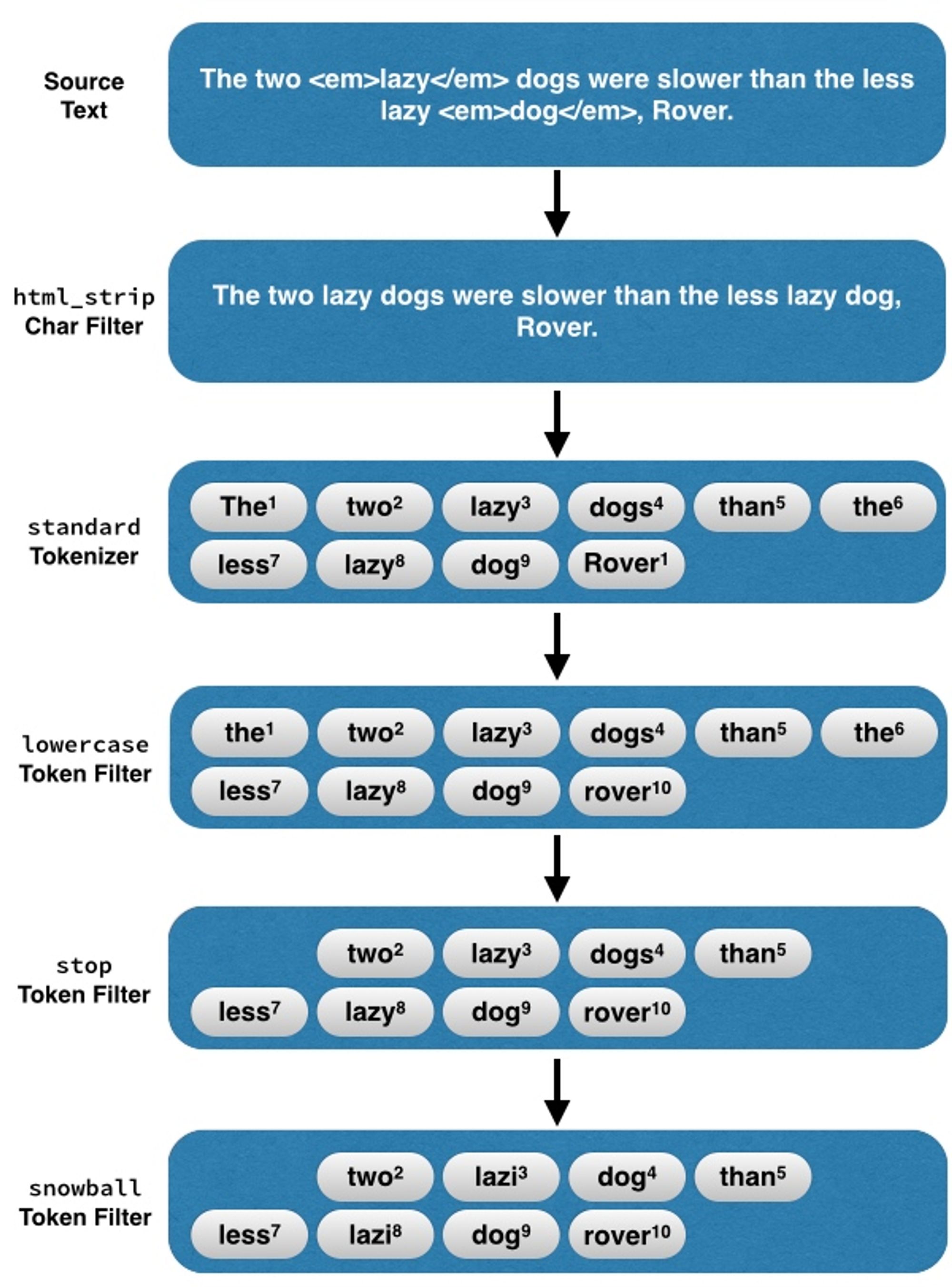
引用一下官方的一个图片:
To quote an official picture:
因此再回头看我们上面的索引的 setting 内容,可以看到我们主要做了如下几个事情:
So looking back at our index setting, we can see that we mainly do the following things:
- 创建一个名为
nick_analyzer的分析器
- 指定其 tokenizer 为
standard(标准分词器)
- 指定 filter 为
stop(去除停用词,如isa)和lowercase(转小写)
- Create a analyzer who was named nick_analyzer
- specify
standard(standard tokenizer) for tokenizer
- specify
stopandlowercasefor filter
这样的一个 nick_analyzer 会有什么样的效果呢,大致处理流程如下:
So what happend in the nick_analyzer? The general processing is as follows:
流程 | 文本 |
开始 | 我最喜欢的 is ElasticSearch |
standard(Tokenizer) | 我、最、喜、欢、的、is、ElasticSearch |
stop(Token Filter) | 我、最、喜、欢、的、ElasticSearch |
lowercase(Token Filter) | 我、最、喜、欢、的、elasticsearch |
这样的话,一段中英文混合的文本,就处理成我们需要的单元保存在索引中了。
In this case, a paragraph of mixed Chinese and English text is processed into the unit we need to save in the index.
number_of_shards
设置索引的数据分片数,ES通过这个选项将索引切分成对应数量的分片。一个索引切成多个分片以后,每个查询请求都会同时在多个分片上处理,这样会大大提升遍历整个索引的速度,提高查询性能。一般的情况下,分片的数量最好小于等于数据节点数。关于
数据节点和非数据节点请参考上一篇文章。This configuration item means setting the shard for a index. The index will be divided into many fragments.After an index is cut, each query request is processed on multiple fragments at the same time, which greatly improves the speed of searching and improves query performance In general, the number of shards should be less or equal to the number of data nodes. You can find more infomation in previous post.
number_of_replicas
这个选项是用来设定索引的数据备份的数量,当集群的节点出现数据丢失时可以通过副本恢复。一般来说设定为1就可以。值得注意的是,通过
GET /_cat/indices查看索引状态时,你会发现设置了number_of_replicas=1所占用的存储空间为number_of_replicas=0的2倍(额外储存了一份备份数据)。数据备份是完全复制原始数据,包括分片设置。假设我们number_of_shards为3,number_of_replicas为1,那么该索引总的分片数量为 3*(1+1)=6。This option is used to set the number of data backups for the index so that data can be recovered from a replica if a node in the cluster loses data. Generally, set it to 1.If you check index status by
GET /_cat/indices ,you will see that the index which setting number_of_replicas=1 takes up twice as much storage space as the index which setting number_of_replicas=0.The replica is a complete copy of the original data, including sharding Settings. So if thenumber_of_shards is 3,the number_of_replicas is 1,that the total numbers of shards for the index is 3(1+1)=6以上就是关于ES的索引配置和管理的内容了。下一期我们继续介绍如何配置实际生产中适用的中文搜索服务。
That's all about index configuration and management for ES. In the next post, we will continue to show you how to configure Chinese search services for actual production.
